source('functions.R')
set.seed(2026) # Para reproducibilidad
# --- DATAFRAME 1: Encuesta General (Para Nominal, Ordinal y Correlaciones) ---
# Usamos codificación numérica subyacente para permitir Correlaciones y Eta
df_encuesta <- data.frame(
Genero = sample(c(1, 2), 200, replace = TRUE),
Sector = sample(c(1, 2, 3, 4), 200, replace = TRUE),
Nivel_Estudios = sample(c(1, 2, 3), 200, replace = TRUE, prob = c(0.2, 0.5, 0.3)),
Nivel_Ingresos = sample(c(1, 2, 3), 200, replace = TRUE, prob = c(0.3, 0.4, 0.3)),
Salario_Anual = rnorm(200, mean = 25000, sd = 5000)
)
df_encuesta <- apply_labels(df_encuesta,
Genero = "Género del encuestado",
Genero = c("Masculino" = 1, "Femenino" = 2),
Sector = "Sector de Empleo",
Sector = c("Agricultura"=1, "Industria"=2, "Servicios"=3, "Tecnología"=4),
Nivel_Estudios = "Nivel Educativo Alcanzado",
Nivel_Estudios = c("Básico" = 1, "Medio" = 2, "Superior" = 3),
Nivel_Ingresos = "Nivel de Ingresos del Hogar",
Nivel_Ingresos = c("Bajo" = 1, "Medio" = 2, "Alto" = 3),
Salario_Anual = "Salario Bruto en Euros"
)
# --- DATAFRAME 2: Estudio Clínico / Fiabilidad (Para 2x2 y Cuadradas) ---
df_clinico <- data.frame(
Tratamiento = sample(c(1, 2), 150, replace = TRUE),
Exito_Intervencion = sample(c(1, 2), 150, replace = TRUE),
Diagnostico_Medico_A = sample(c(1, 2, 3), 150, replace = TRUE),
Diagnostico_Medico_B = sample(c(1, 2, 3), 150, replace = TRUE),
Sector = sample(c(1, 2), 150, replace = TRUE, prob=c(0.4, 0.6))
)
df_clinico <- apply_labels(df_clinico,
Tratamiento = "Grupo de Ensayo",
Tratamiento = c("Control" = 1, "Droga Experimental" = 2),
Exito_Intervencion = "Resultado Clínico",
Exito_Intervencion = c("Fracaso" = 1, "Éxito" = 2),
Diagnostico_Medico_A = "Diagnóstico Dr. Smith",
Diagnostico_Medico_A = c("Sano"=1, "Leve"=2, "Grave"=3),
Diagnostico_Medico_B = "Diagnóstico Dra. Jones",
Diagnostico_Medico_B = c("Sano"=1, "Leve"=2, "Grave"=3)
)10 Asociación
Todo lo anterior queda sustituido por el uso de esta función. En Barbwin se debe replicar este diálogo de SPSS.
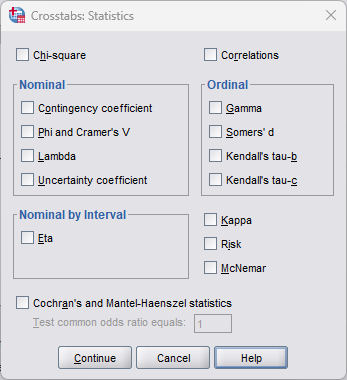
10.1 Pruebas de asociación
- Casos de Uso y Ejecución de PruebasCASO A: Pruebas Nominales y Chi-cuadradoObjetivo: Ver si existe asociación general entre el Género (Nominal) y el Sector de Empleo (Nominal). Al ser variables sin orden lógico, solo aplican las medidas nominales.
bw8crosstabtest(
df = df_encuesta,
row_var = "Genero",
col_var = "Sector",
weight_var = NULL,
chisq = TRUE, # Siempre útil para significación base
phi_cramer = TRUE, # Excelente para tablas rectangulares (2x4)
cont_coef = TRUE,
lambda = TRUE,
uncert_coef = TRUE,
publish = TRUE
)Estadísticos de Tabla Cruzada
Pruebas de Chi-cuadrado
Medidas Simétricas
Medidas Direccionales
CASO B: Pruebas Ordinales y CorrelacionesObjetivo: Ver si a mayor Nivel de Estudios (Ordinal), mayor Nivel de Ingresos (Ordinal). Al tener ambas variables un orden subyacente (1 < 2 < 3), las pruebas ordinales son las indicadas porque tienen en cuenta los empates y la direccionalidad (+/-).
bw8crosstabtest(
df = df_encuesta,
row_var = "Nivel_Estudios",
col_var = "Nivel_Ingresos",
weight_var = NULL,
chisq = TRUE,
correlations = TRUE, # Lanzará Pearson y Spearman (ideal para ordinales)
gamma = TRUE, # Clásico para tablas ordinales
somers_d = TRUE, # Direccional (Asume que Estudios predicen Ingresos)
tau_b = TRUE, # Ideal porque la tabla es cuadrada (3x3)
tau_c = TRUE,
publish = TRUE
)Estadísticos de Tabla Cruzada
Pruebas de Chi-cuadrado
Medidas Simétricas
Medidas Direccionales
CASO C: Prueba Nominal por Intervalo (Eta)Objetivo: Evaluar cuánta varianza del Salario Anual (Intervalo/Continuo) es explicada por el Sector de Empleo (Nominal). Eta es el estadístico idóneo (esencialmente el \(R^2\) de un ANOVA unidireccional).
bw8crosstabtest(
df = df_encuesta,
row_var = "Sector", # Variable Nominal (Grupos)
col_var = "Salario_Anual",# Variable Cuantitativa
weight_var = NULL,
eta = TRUE, # Dispara el ANOVA internamente
publish = TRUE
)Estadísticos de Tabla Cruzada
Medidas Direccionales
CASO D: Pruebas de Fiabilidad y Riesgo (Cuadradas y 2x2)Objetivo 1 (McNemar y Kappa): Ver el nivel de acuerdo entre dos médicos evaluando a los mismos pacientes (Tabla Cuadrada 3x3).Objetivo 2 (Riesgo): Ver si la droga experimental aumenta la probabilidad de éxito frente al control (Tabla 2x2).R# Test de Acuerdo (Tabla 3x3 Cuadrada)
bw8crosstabtest(
df = df_clinico,
row_var = "Diagnostico_Medico_A",
col_var = "Diagnostico_Medico_B",
weight_var = NULL,
kappa = TRUE, # Indice de concordancia de Cohen
mcnemar = TRUE, # Prueba de simetría marginal
publish = TRUE
)Estadísticos de Tabla Cruzada
Medidas Simétricas
Otras Pruebas
# Test de Riesgo (Tabla estrictamente 2x2)
bw8crosstabtest(
df = df_clinico,
row_var = "Tratamiento",
col_var = "Exito_Intervencion",
weight_var = NULL,
chisq = TRUE, # Pearson base
risk = TRUE, # Dispara el cálculo de la Odds Ratio
publish = TRUE
)Estadísticos de Tabla Cruzada
Pruebas de Chi-cuadrado
Otras Pruebas
bw8crosstabtest(
df = df_clinico,
row_var = "Tratamiento",
col_var = "Exito_Intervencion",
weight_var = NULL,
layer_var = "Sector",
chisq = TRUE, # Pearson base
cmh = TRUE, cmh_odds = 1,
publish = TRUE
)Estadísticos de Tabla Cruzada
Pruebas de Chi-cuadrado
Otras Pruebas
10.1.1 Correspondencia UI (Barbwin8) -> Función R
Así es como tu equipo de desarrollo debe mapear las casillas del cuadro de diálogo a los argumentos de la función:
Chi-square➔chisq = TRUECorrelations➔correlations = TRUEContingency coefficient➔cont_coef = TRUEPhi and Cramer's V➔phi_cramer = TRUELambda➔lambda = TRUEUncertainty coefficient➔uncert_coef = TRUEGamma➔gamma = TRUESomers' d➔somers_d = TRUEKendall's tau-b➔tau_b = TRUEKendall's tau-c➔tau_c = TRUEEta➔eta = TRUEKappa➔kappa = TRUERisk➔risk = TRUEMcNemar➔mcnemar = TRUECochran's and Mantel-Haenszel...➔cmh = TRUE(requiere pasar una tercera variable en el argumentolayer_var).