source('functions.R')17 Análisis de Correspondencias Simples
17.1 Revisión 109
La revisión 109 anula todo lo anterior.
Se parte de un fichero de datos abierto que contiene la tabla de datos a representar. Aunque lo normal fuera que la primera columna fuera el id_var y el resto las vars, pueden estar en cualquier orden.
17.1.1 Diálogo
En el diálogo se debe pedir:
- Variable que contiene los textos de las filas
- Variables a analizar (activas / no activas) que contienen las mediciones
- Variables que son suplementarias (supcol), se recogerá el índice de 1 a k (orden en el dataframe)
- Filas suplementarias se recoge el nº de fila (??? no sé como indicarlo)
- nd, número de dimensiones a retener. Número que irá desde 2 a z, siendo z el menor de columnas o filas descontando las suplementarias
- map_type = (“symmetric”), método de presentación del mapa:
- “symmetric” (default)
- “rowprincipal”
- “colprincipal”
- “symbiplot”
- “rowgab”
- “colgab”
- “rowgreen”
- “colgreen”
- mass_scale = c(FALSE, FALSE), tamaño punto según masa que implica si el punto se representa en tamaño según su masa, más masa más grande el punto. Se puede discriminar entre filas / columnas c(TRUE,FALSE) o c(FALSE,TRUE),
- contrib_type = c(“none”, “none”),
- “none” (contributions are not indicated in the plot).
- “absolute” (absolute contributions are indicated by colour intensities)
- “relative” (relative contributions are indicated by colour intensities)
- arrows_opt = c(FALSE, FALSE), sirve para pintar las flechas desde origen. Se puede discriminar entre filas / columnas c(TRUE,FALSE) o c(FALSE,TRUE).
Aunque aqui pongo un ejemplo en el que creo el dataframe, lo que espera es un dataframe con la estructura de la tabla.
En este ejemplo que tenemos abajo, el fichero que tendríamos sería este:
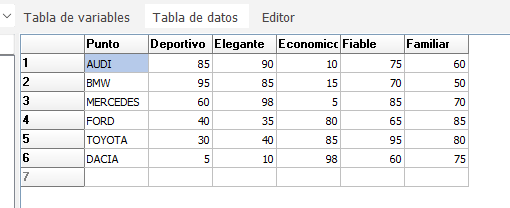
# 1. Matriz de frecuencias (Menciones de consumidores)
# La primera columna es el identificador (id_var) y el resto las categorías numéricas
datos_coches <- data.frame(
Marca = c("Audi", "BMW", "Mercedes", "Ford", "Toyota", "Dacia"),
Deportivo = c(85, 95, 60, 40, 30, 5),
Elegante = c(90, 85, 98, 35, 40, 10),
Economico = c(10, 15, 5, 80, 85, 98),
Fiable = c(75, 70, 85, 65, 95, 60),
Familiar = c(60, 50, 70, 85, 80, 75),
stringsAsFactors = FALSE
)
# 2. Aplicación de etiquetas de variable (Simulación metadatos SPSS)
# Estas son las etiquetas largas que la función bw8ca() detectará para las tablas
datos_coches <- apply_labels(datos_coches,
Deportivo = "Diseño aerodinámico y rendimiento deportivo",
Elegante = "Estilo clásico, lujo y representación",
Economico = "Precio asequible y bajo consumo",
Fiable = "Mecánica robusta, duradera y sin averías",
Familiar = "Amplitud y comodidad para la familia"
)
# 3. Llamada al motor de correspondencias
bw8ca(
df = datos_coches,
vars = c("Deportivo", "Elegante", "Economico", "Fiable", "Familiar"),
id_var = "Marca",
suprow = NULL,
supcol = NULL,
nd = 3,
map_type = "symmetric",
mass_scale = c(TRUE, TRUE),
contrib_type = c("relative", "relative"),
arrows_opt = c(FALSE, FALSE),
publish = TRUE
)Análisis de correspondencias simple (CA)
Tabla de correspondencias
Perfiles de fila
Perfiles de columna
Prueba de homogeneidad
Residuos estandarizados corregidos
Modelo (inercias)
Coordenadas y contribuciones (fila)
Coordenadas y contribuciones (columna)
Mapa de correspondencias (proyección: symmetric )
